





The Affect of Methodological Selections on Machine Studying Portfolios
Research utilizing machine studying methods for return forecasting have proven appreciable promise. Nonetheless, as in empirical asset pricing, researchers face quite a few selections round sampling strategies and mannequin estimation. This raises an necessary query: how do these methodological selections impression the efficiency of ML-driven buying and selling methods? Latest analysis by Vaibhav, Vedprakash, and Varun demonstrates that even small selections can considerably have an effect on general efficiency. It seems that in machine studying, the previous adage additionally holds true: the satan is within the particulars.
This simple paper is a wonderful reminder that methodological selections in machine studying (ML) methods (resembling utilizing EW or VW weighting, together with micro caps, and so forth.) considerably impression the outcomes. It’s essential to think about these selections like conventional cross-sectional issue methods, and practitioners resembling portfolio managers ought to all the time preserve this in thoughts earlier than deploying such a technique.
The novel integrations of AI (synthetic intelligence) and deep studying (DL) methods into asset-pricing fashions have sparked renewed curiosity from academia and the monetary business. Harnessing the immense computational energy of GPUs, these superior fashions can analyze huge quantities of monetary knowledge with unprecedented pace and accuracy. This has enabled extra exact return forecasting and has allowed researchers to sort out methodological uncertainties that have been beforehand troublesome to deal with.
Outcomes from greater than 1152 alternative mixtures present a sizeable variation within the common returns of ML methods. Utilizing value-weighted portfolios with measurement filters can curb an excellent portion of this variation however can not remove it. So, what’s the resolution to non-standard errors? Research in empirical asset pricing have proposed numerous options. Whereas Soebhag et al. (2023) counsel that researchers can present outcomes throughout main specification selections, Walter et al. (2023) argue in favor of reporting the whole distribution throughout all specs.
Whereas the authors of this paper agree with reporting outcomes throughout variations, it’s clever to advise towards a one-size-fits-all resolution for this difficulty. Regardless of an in depth computation burden, It’s attainable to compute and report the whole distribution of returns for characteristic-sorted portfolios, as in Walter et al. (2023). Nonetheless, when machine studying strategies are used, documenting distribution as an entire will probably impose an excessive computational burden on the researcher. Though a whole distribution is extra informative than a partial one, the prices and advantages of each selections have to be evaluated earlier than giving generalized suggestions.
What are extra methods to manage for methodological variation whereas imposing a modest burden on the researcher? Frequent suggestions favor first figuring out high-impact selections (e.g., weighting and measurement filters) on a smaller-scale evaluation. Researchers can then, on the very least, report variations of outcomes throughout such high-priority specs whereas holding the remainder optionally available.
Authors: Vaibhav Lalwani, Vedprakash Meshram, and Varun Jindal
Title: The impression of Methodological selections on Machine Studying Portfolios
Hyperlink: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4837337
Summary:
We discover the impression of analysis design selections on the profitability of Machine studying funding methods. Outcomes from 1152 methods present that appreciable variation is induced by methodological selections on technique returns. The non-standard errors of machine-learning methods are sometimes greater than the usual errors and stay sizeable even after controlling for some high-impact selections. Whereas eliminating micro-caps and utilizing value-weighted portfolios reduces non-standard errors, their measurement continues to be quantitatively similar to the standard customary errors.
As all the time, we current a number of thrilling figures and tables:


Notable quotations from the educational analysis paper:
“[T]right here is ample proof that implies that researchers can use ML instruments to develop higher return forecasting fashions. Nonetheless, a researcher must make sure selections when utilizing machine studying in return forecasting. These selections embrace, however usually are not restricted to the scale of coaching and validation home windows, the end result variable, knowledge filtering, weighting, and the set of predictor variables. In a pattern case with 10 determination variables, every providing two determination paths, the overall specification are 210, i.e. 1024. Accommodating extra advanced selections can result in hundreds of attainable paths that the analysis design may take. Whereas most research combine some stage of robustness checks, maintaining with the whole universe of prospects is nearly unattainable. Additional, with the computationally intensive nature of machine studying duties, this can be very difficult to discover the impression of all of those selections even when a researcher needs to. Due to this fact, a few of these calls are often left to the higher judgment of the researcher. Whereas the sensitivity of findings to even apparently innocent empirical selections is well-acknowledged within the literature1, we’ve got solely very lately begun to acknowledge the scale of the issue at hand. Menkveld et al. (2024) coin the time period to Non-standard errors to indicate the uncertainty in estimates on account of completely different analysis selections. Research like Soebhag et al. (2023) and Walter et al. (2023), and Fieberg et al. (2024) present that non-standard errors might be as massive, if not bigger than conventional customary errors. This phenomenon raises necessary questions in regards to the reproducibility and reliability of monetary analysis. It underscores the necessity for a presumably extra systematic strategy to the selection of methodological specs and the significance of transparency in reporting analysis methodologies and outcomes. As even seemingly innocuous selections can have a big impression on the ultimate outcomes, except we conduct a proper evaluation of all (or no less than, most) of the design selections collectively, will probably be exhausting to know which selections matter and which don’t by means of pure instinct.Even in asset-pricing research that use single attribute sorting, there are literally thousands of alternatives (Walter et al. (2023) use as many as 69,120 potential specs). Extending the evaluation to machine learning-based portfolios, the attainable checklist of selections (and their attainable impression) additional expands. Machine-learning customers must make many extra selections for modeling the connection between returns and predictor traits. With the variety of machine studying fashions obtainable, (see Gu et al. (2020) for a subset of the attainable fashions), it might not be unfair to say that students within the discipline are spoilt for selections. As argued by Harvey (2017) and Coqueret (2023), such numerous selections may exacerbate the publication bias in favor of constructive outcomes.
Curiosity in functions of Machine studying in Finance has grown considerably within the final decade or so. Because the seminal work of Gu et al. (2020), many variants of machine studying fashions have been used to foretell asset returns. Our second contribution is to this rising physique of literature. That there are a lot of selections whereas utilizing ML in return forecasting is effectively understood. However are the variations between specs massive sufficient to warrant warning? Avramov et al. (2023) exhibits that eradicating sure varieties of shares significantly reduces the efficiency of machine studying methods. We develop this line of thought utilizing a broader set of selections that embrace numerous issues that hitherto researchers may need ignored. By offering a big-picture understanding of how the efficiency of machine studying methods varies throughout determination paths, we conduct a type of large-scale sensitivity evaluation of the efficacy of machine studying in return forecasting. Moreover, by systematically analyzing the results of assorted methodological selections, we are able to perceive which components are most infuential in figuring out the success of a machine learning-based funding technique.
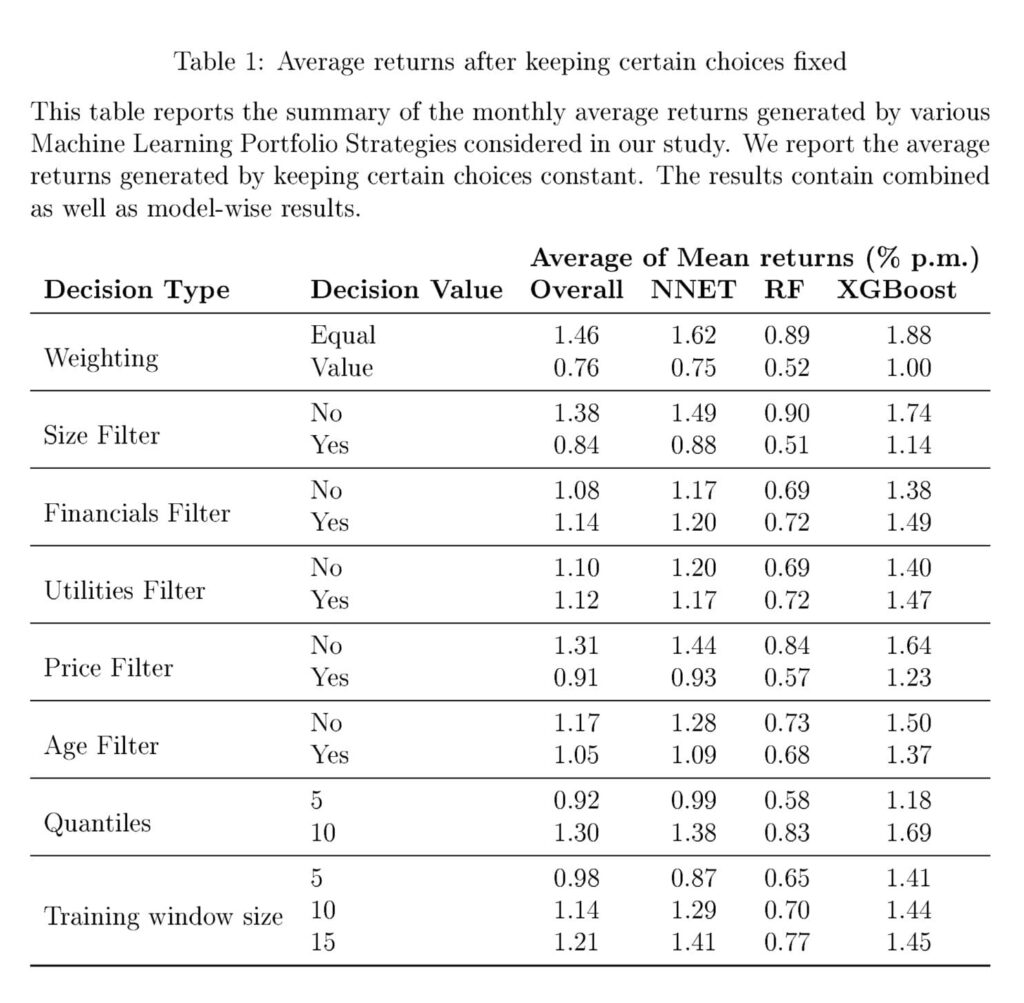
To summarise, we discover that the alternatives concerning the inclusion of micro-caps and penny shares and the weighting of shares have a big impression on common returns. Additional, a rise in sampling window size yields greater efficiency, however massive home windows usually are not wanted for Boosting-based methods. Based mostly on our outcomes, we argue that financials and utilities shouldn’t be excluded from the pattern, no less than not when utilizing machine studying. Sure methodological selections can cut back the methodological variation round technique returns, however the non-standard errors stay sizeable.
Determine 1 exhibits the distribution of returns throughout numerous specs. We observe a non-trivial variation within the month-to-month common returns noticed throughout numerous selections. The variation seems to be a lot bigger for equally-weighted portfolios in comparison with value-weighted portfolios, a outcome we discover fairly intuitive. The determine additionally factors in direction of a couple of massive outliers. It will be fascinating to additional analyze if these excessive values are pushed by sure specification selections or are random. The variation in returns might be pushed by the selection of the estimator. Research like Gu et al. (2020) and Azevedo et al. (2023) report vital variations between returns from utilizing completely different Machine Studying fashions. Due to this fact, we plot the return variation after separating fashions in Determine 2. Determine 2 makes it obvious that there’s a appreciable distinction between the imply returns generated by completely different ML fashions. In our pattern, Boosted Timber obtain the very best out-of-sample efficiency, carefully adopted by Neural Networks. Random Forests seem to ship a lot decrease efficiency in comparison with the opposite two mannequin sorts. Additionally, Determine 2 exhibits that the general distribution of efficiency is analogous for uncooked returns in addition to Sharpe Ratios. Due to this fact, for the remainder of our evaluation, we contemplate long-short portfolio returns as the usual metric of portfolio efficiency.All in all, there’s a substantial variation within the returns generated by long-short machine studying portfolios. This variation is unbiased of the efficiency variation on account of alternative of mannequin estimators. We now shift our focus towards understanding the impression of particular person selections on the typical returns generated by every of the specs. Due to this fact, we estimate the typical of the imply returns for all specs whereas holding sure selections fastened. These outcomes are in Desk 1.The leads to Desk 1 present that some selections impression the typical returns greater than others. Equal weighting of shares within the pattern will increase the typical returns. So does the inclusion of smaller shares. The inclusion of monetary and utilities seems to have a barely constructive impression on the general portfolio Efficiency. Identical to a measurement filter, the exclusion of low-price shares tends to scale back general returns. Additional, grouping shares in ten portfolios yields higher efficiency in comparison with quintile sorting. On common, bigger coaching home windows seem like higher. Nonetheless, this appears to be true largely for Neural Networks. For Neural Networks, the typical return will increase from 0.87% to 1.41% monthly. For enhancing, the achieve is from 1.41% to 1.45%. XGBoost works effectively with simply 5 years of information. It takes no less than 15 years of information for Neural Networks to attain the identical efficiency. Curiously, whereas Gu et al. (2020) and (Avramov et al., 2023) each use Neural Networks with a big increasing coaching window, our outcomes present that related efficiency might be achieved with a a lot smaller knowledge set (however with XGBoost). Lastly, the method of holding solely shares with no less than two years of information reduces the returns, however as mentioned, this filter makes our outcomes extra relevant to real-time traders.”
Are you searching for extra methods to examine? Join our publication or go to our Weblog or Screener.
Do you need to study extra about Quantpedia Premium service? Examine how Quantpedia works, our mission and Premium pricing supply.
Do you need to study extra about Quantpedia Professional service? Examine its description, watch movies, assessment reporting capabilities and go to our pricing supply.
Are you searching for historic knowledge or backtesting platforms? Examine our checklist of Algo Buying and selling Reductions.
Or observe us on:
Fb Group, Fb Web page, Twitter, Linkedin, Medium or Youtube
Share onLinkedInTwitterFacebookConsult with a pal






")



